JDL Level 5 Fusion Model “User Refinement”
Issues and Applications
in Group Tracking
Erik. P. Blasch1 and
1 – Department of Electrical Engineering, 2 – Department of Biomedical and Industrial Engineering
Wright State University, Dayton, Ohio
ABSTRACT
The 1999 Joint Director of Labs (JDL) revised model
incorporates five levels for fusion methodologies including level 0 for
preprocessing, level 1 for object refinement, level 2 for situation refinement,
level 3 for threat refinement, and level 4 for process refinement. The model was developed to define the fusion
process. However, the model is only for automatic processing of a machine and
does not account for human processing.
Typically, a fusion architecture supports a
user and thus, we propose a Level 5 “User refinement” to delineate the
human from the machine in the process refinement. Typical “human in the loop”
models do not deal with a machine fusion process, but only present the
information to the human on a display.
We seek to address issues for designing a fusion system which supports a
user: trust, workload, attention and situation
awareness. In this paper, we overview
the need for a Level 5, the issues concerning the human for realizable fusion
architectures, and examples where the human is instrumental in the fusion
process such as group tracking.
Keywords: Information Fusion, Group Tracking, Identity, workload, attention, situation awareness, trust, HMI, HCI
1. INTRODUCTION
The fusion and tracking community has developed refined mathematical algorithms from which to track targets based on sensed positional measurement information [1]. Human visual tracking [2] incorporates the inherent process of motion detection and subsequently sequencing measurement information. The integration of these methods is the fusion of the human motion processing of observed target identity (ID) and mathematical-machine positional information[3]. Tracking ultimately is performed for human needs, whether it be for surveillance applications or object assessment (i.e. air traffic control). Industrial systems have sometimes employed fusion technology, however, the goal was to present target localization as opposed to developing a strategy for man-machine fusion-tracking interactions. Limited research has been performed in the area of incorporating a human into the standard fusion models. Here, we see the human as an active component in the fusion process to optimize sensors to best locate and ID targets.
There are many sensor fusion architectures and some have evolved with time. Machines are quick at data processing and it is time for higher level fusion issues to be addressed to incorporate the human in the loop. We are interested in breaking up the high-level sensor management task into two areas – one for the computer and one for the human. The human is interested in many aspects that can not be programmed into the computer – such as online strategies dealing with measurement process uncertainties and wide area surveillance. Humans are excellent in monitoring and controlling the fusion process. In the future, one could argue that the human and the fusion system might be able to interact in an adaptive way, however a new fusion paradigm would be needed to leverage the human’s intelligent reasoning skills [3]. The human brain, with the prefrontal cortex performing higher level reasoning and attentional functions, can work to control the fusion process to insure that the correct associations are performed by the machine.
Section 2 overviews fusion and user models for human-machine interaction (HMI). Section 3 overviews the JDL-user model that incorporates Level 5 User Refinement. Section 4 addresses issues of situation awareness, attention, workload, and trust needed in Level 5. Section 5 presents simulated results. Section 6 draws conclusions and ongoing efforts.
2. Human-Machine Fusion
Information fusion exists in many forms, such as integrating audio and visual data, plans, or surveillance requirements. It is important to remember that the goal of any model is to extend the sensing capabilities of the human to prosecute his or her environment. To effectively input, fuse, and output actions, models help to illustrate these functions.
2.1 Information Fusion Models
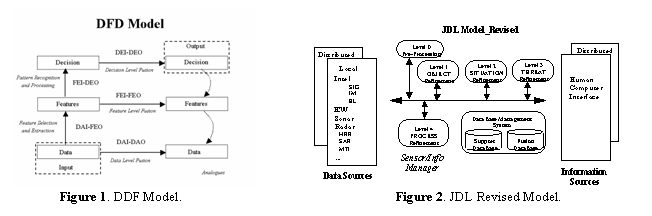
Two models that are fusion-focused are the Data-Feature-Decision (DFD) [4] model and the traditional Joint Director’s of Labs (JDL) model [5], shown in Figure 1 and Figure 2 respectively. Dasarathy introduced the DFD model to guide a machine to make decisions based on the data. The JDL model consists of five modules with a human computer interface. While the model has been the standard for military research and fusion discussion, it needs to be adapted to reflect the importance of the human for information exploitation. The exploitation of information includes control, decision, and action. In the revised JDL model, it can be stated that the Level 4 process refinement might include both the user and sensor control functions as feedback for refining the fusion process.
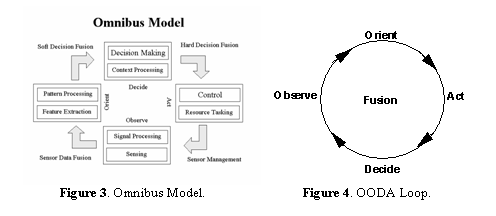 The Ominbus model
[4], shown in Figure 3, is an extension of the OODA control loop (sometimes
referred to as the Boyd control loop) as shown in Figure 4. In the case of the OODA and the Omnibus
model, the machine is central to the model and is based on a human reasoning
strategy.
The Ominbus model
[4], shown in Figure 3, is an extension of the OODA control loop (sometimes
referred to as the Boyd control loop) as shown in Figure 4. In the case of the OODA and the Omnibus
model, the machine is central to the model and is based on a human reasoning
strategy.
2.2. User Models
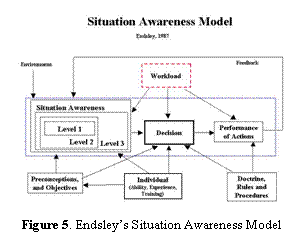 The
Human in the Loop (HIL) of a semi-automated system must be given adequate
situation awareness (SA). According to a pioneer and continued leader in the SA
literature, Endsley stated that "Situation awareness is the perception of
the elements in the environment within a volume of time and space, the
comprehension of their meaning, and the projection of their status in the near
future.” [6, 7, 8]. This now-classic model translates
into 3 levels:
The
Human in the Loop (HIL) of a semi-automated system must be given adequate
situation awareness (SA). According to a pioneer and continued leader in the SA
literature, Endsley stated that "Situation awareness is the perception of
the elements in the environment within a volume of time and space, the
comprehension of their meaning, and the projection of their status in the near
future.” [6, 7, 8]. This now-classic model translates
into 3 levels:
•
Level 1
SA - Perception of elements in the environment.
•
Level 2
SA - Comprehension of the current situation
•
Level 3
SA - Projection of future states
Operators of
dynamic systems use their situation awareness in determining their
actions. To optimize decision making,
the SA provided by a system should be as precise as possible as to the objects
in the environment (Level 1 SA). A situation awareness approach should present a
fused representation of the data (Level 2 SA) and provide support for the
operator's projection needs (Level 3 SA) in order to facilitate operator's
goals. From
the
SA model presented in Figure 5, workload is a key component of the model that
affects not only SA, but also the decision and the action of the user.
![Text Box:
Figure 6. Perceptual Reasoning [Kadar SPIE02].](Level5Group_files/image010.gif) Research areas concerned with SA include 1) Military (e.g.,
Research areas concerned with SA include 1) Military (e.g.,
2.3 User Designed Fusion Models
Two of the current user fusion models are the perceptual and the Neurophysiology models. An example of the perceptual reasoning machine (PRM) by Kadar [10] is shown in Figure 6. The model incorporates the prior information that the user has to help guide the prediction of the system. Current human knowledge can estimate the situation. Kadar uses the model to address the information gathering for actions pertinent to the user.
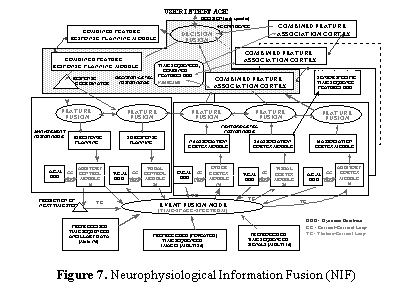 While perception is
a psychological construct, we can also address the user needs by addressing the
biology of the human in the fusion process. Human fusion of several sensor
modalities is expressed in the Neurophysiological Information Fusion (NIF)
architecture. The sensor modalities
considered include visual, auditory, and somatosensory to locate a target. The visual system is composed of the eyes,
the thalamic, the superior colliculus, and the primary visual cortex. When a person is “searching” a region of space, he is looking for objects or
events. To anticipate the location of
the object, the person predicts what the target looks like and maps that image
prediction onto a consistent, stable model of his environment. After an object is detected, (i.e. listening for a
threat warning) a cue guides a person to look for the target amongst objects in
the common operation picture (COP). The
auditory system can cue the visual system to the general target location, but
where and when should the visual system start looking? A higher-level cognitive function of extraction
is needed to associate
information. Using a feature-based
extraction approach from the cued visual image is essential to the model. To further combine biological, perceptual,
and machine-fusion, we explore elements of “User Refinement”.
While perception is
a psychological construct, we can also address the user needs by addressing the
biology of the human in the fusion process. Human fusion of several sensor
modalities is expressed in the Neurophysiological Information Fusion (NIF)
architecture. The sensor modalities
considered include visual, auditory, and somatosensory to locate a target. The visual system is composed of the eyes,
the thalamic, the superior colliculus, and the primary visual cortex. When a person is “searching” a region of space, he is looking for objects or
events. To anticipate the location of
the object, the person predicts what the target looks like and maps that image
prediction onto a consistent, stable model of his environment. After an object is detected, (i.e. listening for a
threat warning) a cue guides a person to look for the target amongst objects in
the common operation picture (COP). The
auditory system can cue the visual system to the general target location, but
where and when should the visual system start looking? A higher-level cognitive function of extraction
is needed to associate
information. Using a feature-based
extraction approach from the cued visual image is essential to the model. To further combine biological, perceptual,
and machine-fusion, we explore elements of “User Refinement”.
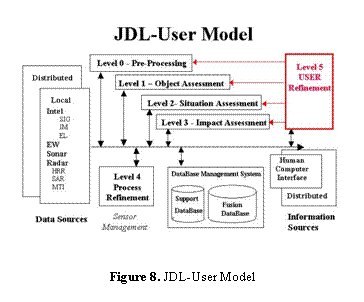
3. The JDL-U Sensor Fusion Model
The JDL-U model activities are:
Level 0 - Sub-Object Data Assessment: estimation and prediction of signal/object
observable states on the basis of pixel/signal level data association (e.g.
information systems collections);
Level 1 - Object Assessment:
estimation and prediction of entity states on the basis of
observation-to-track association, continuous state estimation and discrete
state estimation (e.g. data processing);
Level 2 - Situation Assessment:
estimation and prediction of relations among entities, to include force
structure and force relations, communications, etc. (e.g. information
processing,
 Level 3 - Impact Assessment: estimation and prediction of effects on
situations of planned or estimated actions by the participants; to include
interactions between action plans of multiple players (e.g. assessing threat
actions to planned actions and mission requirements, DM, PE);
Level 3 - Impact Assessment: estimation and prediction of effects on
situations of planned or estimated actions by the participants; to include
interactions between action plans of multiple players (e.g. assessing threat
actions to planned actions and mission requirements, DM, PE);
Level 4 - Process Refinement (an element of Resource Management): adaptive data acquisition and processing to support mission objectives (e.g. sensor management and information systems dissemination, IO, C2).
Level 5 - User Refinement (an element of Knowledge Management): adaptive determination of who queries information and who has access to information. (e.g. information operations) and adaptive data retrieved and displayed to support cognitive decision making and actions (e.g. altering the sensor display).
The key to the fusion process is data association. Difficulties of using data association fusion are that: sensor data can be unreliable, the transfer process may corrupt data, or inappropriate information fusion actions may occur. By assessing the data (level 0 – 1) with information (level 2 and 3), sensor management and user refinement (level 4 and 5) can correct for these fusion errors.
 Process
refinement controls information flow.
User refinement guides data collection, region of coverage, situation
and threat assessment as well as process refinement of sensor selections. While
each level needs fused information from lower levels, the refinement of fused
information is a function of the user. Two important issues are control of the information and the planning of actions. There are many
issues related to centralized and distributed control such as team management
and individual survivability. For
example, an Army Tactical Operational Center (TOC) display, shown in Figure 9,
might be globally distributed, but centralized for a single commander for local
operations. [see 11 for another example]. Thus, the
information displayed on a human computer interface should not only reflect the
information received from lower levels, but also afford analysis and
distribution of commander actions, directives, and missions. Once actions are taken, new observable data
should be presented as a operational feedback
information. Likewise, the analysis
should include the local and global operational changes and the confidence of
new information. Finally, execution should
include updates to the distributed system of orders, plans, and actions to
people carrying out mission directives.
Thus, Level 4, it is not the fusing of signature, image, and track
intelligence data, but that of fusion of decision intelligence (DECINT)
information for functionality.
Process
refinement controls information flow.
User refinement guides data collection, region of coverage, situation
and threat assessment as well as process refinement of sensor selections. While
each level needs fused information from lower levels, the refinement of fused
information is a function of the user. Two important issues are control of the information and the planning of actions. There are many
issues related to centralized and distributed control such as team management
and individual survivability. For
example, an Army Tactical Operational Center (TOC) display, shown in Figure 9,
might be globally distributed, but centralized for a single commander for local
operations. [see 11 for another example]. Thus, the
information displayed on a human computer interface should not only reflect the
information received from lower levels, but also afford analysis and
distribution of commander actions, directives, and missions. Once actions are taken, new observable data
should be presented as a operational feedback
information. Likewise, the analysis
should include the local and global operational changes and the confidence of
new information. Finally, execution should
include updates to the distributed system of orders, plans, and actions to
people carrying out mission directives.
Thus, Level 4, it is not the fusing of signature, image, and track
intelligence data, but that of fusion of decision intelligence (DECINT)
information for functionality.
DECINT information is a globally and locally refined assessment of fused observational information. DECINT is the information for which a user can act on. Additionally, HUMINT data can be gathered from other people to determine what information to collect, analyze, and distribute to others. One way to facilitate the receiving, analyzing, and distribution of actions is that of the observe, orient, decide, and act (OODA) loop. The OODA loop requires the display of information for functional cognitive decision-making. In this case, the display of information should orient a person as in determining the situation based on the observed information (i.e. situation assessment). These actions need to be assessed from the user ability to deploy his resources against the resources, constraints, and opportunities of the environment.
The processing of information can be labeled as action intelligence (ACTINT) information because an assessment of possible/plausible actions needs to be considered. Thus, the goal of any fusion system is to provide the user a set of refined information for functional action. Taken together, the fusion system is actually a functional sensor for the user, whereas the traditional fusion models are just an observational sensor. The user refinement block not only is the determination of who wants the information and if they can refine the information, but how they process the information. Bottom-up processing of information can take the form of physical sensed quantities that support the higher-level functions. To include the automation as well as the user, it is important to view the user through an interface which the user can interact with the system (i.e. sensors). In this case, the user can query necessary information to make a decision while the automated system can work in the background to update the changing environment. Additionally, the functional fusion system is concerned with the entire situation while a user is typically interested in only a subsection of the environment. The computer has to try many combinations, but the human is adapt to locating the objects using sensor fusion.
Target ID and localization information is the desired result of either real or perceived data from a time and space representation. The difficulty with presenting the complete set of real data is the shear amount available. For example, A person monitoring many region of interest (ROI)s, waits for some event or threat to come into the sensor domain. In continuous collection modes, most sensor data is entirely useless. Useful data occurs when a sensed event interrupts the monitoring system and initiates a threat update. Decision-makers only need a subset of the entire data to perform successful SA and impact assessment. More importantly the user needs a time-event update on the target of interest. Thus, data reduction must be performed. The advantage of reducing the incoming data can especially be realized by using a fusion strategy over time as well as space. Target data can be fused into a single COP for enhanced SA.
An inherent difficulty resides in the fusion of only two forms of data. If one sensor perceives the correct target and the other does not, there is a conflict. Sensor conflicts increase the cognitive workload that must be reduced. However, if time, space, and spectral event fusion from different sensors, conflicts can be resolved within an emergent process to allow for better decisions over time. The strategy is to employ multiple sensors from multiple perspectives as shown in the proposed NIF model which characterizes the Level 5 user refinement system in the JDL-U model. Additionally, the HCI can be used to give the user a global and local SA to guide attention and reduce workload.
4. Level 5 – User Refinement Issues
4.1 Workload
Muir and Moray, 1996 [12], observed that “A need to understand the interaction between human operators and automation has been created by the arrival of complex, dynamic, intelligent automation.” Workload of the User was a different issue in automated systems, and not well described or measured. Endsley and colleagues present novel taxonomies and review the literature for Levels of Automation (LOA). [13] When considering workload components and impacts upon outcome in semi-automated systems, the appropriate LOA for the mission of the system must be experimentally researched and subsequently designed into the HIL system. LOA run the gamut, regardless of which LOA model is adopted, from manual (human) control to fully automated (no HIL) systems.
 Workload measures and analysis becomes
critically important as it is a confounder in the relationships of the other
attention factors upon human performance. Current widely used workload measures
in military, especially flight, applications include the objective SAGAT
battery [6, 8] and both the SART inventory [14] or the NASA-TLX (Task Load
Index) [15] for subjective measures of workload. Training, or the novice or
expert status of the HIL with respect to the automation, must be taken into
account, as it affects objective and subjective measures of workload.
Subjective measures of workload are strongly correlated with perceived success
of decision making.
Workload measures and analysis becomes
critically important as it is a confounder in the relationships of the other
attention factors upon human performance. Current widely used workload measures
in military, especially flight, applications include the objective SAGAT
battery [6, 8] and both the SART inventory [14] or the NASA-TLX (Task Load
Index) [15] for subjective measures of workload. Training, or the novice or
expert status of the HIL with respect to the automation, must be taken into
account, as it affects objective and subjective measures of workload.
Subjective measures of workload are strongly correlated with perceived success
of decision making.
4.2 Attention
Any consideration of Level 5 User Refinement must incorporate known human factors of attention and workload upon SA and decision making. Elements of attention which are relevant include multimodal informational inputs. Primary modalities are visual and auditory systems, but tactile/haptic sensory channels are gaining research and design focus. Endsley [16] outlines key factors impinging upon attention include
- syntax, semantics, and clutter of presented information from prior system Levels,
- novice vs. expert status with the system,
- visual search strategies, auditory identification strategies, and
- training with respect to efficiency and efficacy of strategies
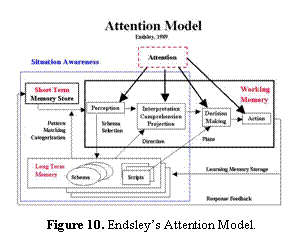
Theories of attention modeling that are relevant for SA
include mental modeling and situational modeling, as shown in Figure 10. Mental
modeling addresses the memory available to the human and processes for
employing it. Typically, three forms of
memory are discussed: short, working, and long-term memory. Since the human can only process a subset of
the information available (i.e. 7 items at a time), the presentation of information
to the human has to account for the amount that can be processed by working
memory, and what types of search, salience recognition, and processing
strategies are involved in the mission.
Endsley outlines a key long-term
memory construct [16] which includes (a) episodic memory, pertaining to
object-time-location data from self-referent episodes (b) semantic networks,
pertaining to the conceptual meaning of data and the relationship links or
rules that the user accords the data, and (c) schema, which more broadly
encompasses general knowledge, organized into structures like frames, plans, or
scripts. [17]
Another construct of memory Endsley outlines [16] delineates mental vs. situational models. A mental model [18] is a mechanism whereby humans generate descriptions of purpose, explanations of system functions from observed system states, and predictions of future states. Another way to describe mental models is a complex schema that are plans of actions. A situational model [19] is a schemata depicting the current state of the system model Rasmussen [20] describes a situational model as a world model in his skills, rules, and knowledge model. A model of the current situation model can be viewed as a schema in memory that activates associated goals or scripts. Endsley notes that schema and mental models are developed with experience for a given environment and task. Initially, a human is a novice having only a vague idea of system components and rough heuristics to employ. With experience, recurrent situational components, associations, and causal relationships will develop such that a person becomes an expert.
These cognitive models are a critical starting point for the automation designer in overcoming working memory limitations by utilizing strengths in long term memory to assist short-term tasks and multi-modal search strategies. The next important point for automation designers are the classic theories of attention, especially in the visual domain. Five key theories can be summarized as follows [21 – 24]:
• Early Selection Theory (or Broadbent’s Filter Theory) - Early filtering of stimuli, generally by physical dimensions of signal input, results in one component ‘message’ being selected and propagated to downstream processing for efficiency. Other ‘messages’ are lost in this early filter. Efficiency takes priority over validity and mitigating error.
• Attenuation Theory - ‘Messages’ are weighted with priority given to one message over the others; the former receives full processing (if this can be defined and analyzed) while latter receive only partial processing.
• Late Selection Theory - Efficiency is sacrificed for validity and reduced error: All ‘messages’, attended or not, undergo semantic analysis and receive downstream processing, after which the key ‘message’ is determined since only one response can be made.
• Object Based Theory- Rather than relying on physical parameters of input, a visual scene is dissected into distinct perceptual ‘objects’. Leaving aside the selection of the salient ‘message’, the focus here is upon implications of how the scene is processed: parallel processing is theorized for object features while serial processing is theorized between objects. This theory informs research on guided search strategies within a field of view or a display.
•
 Space-based theory- Again leaving
aside the selection of the salient information or ‘message’ of input data, the
“spotlight” approach concerns the narrow field of view upon a scene, within
which the visual attention is focused. Parallel
search (at the same time) might be a target and location whereas serially
(one at a time) includes searching for multiple targets. Everything within the spot can be processed
in parallel; things outside the spot, or peripheral vision, are processed
serially.
Space-based theory- Again leaving
aside the selection of the salient information or ‘message’ of input data, the
“spotlight” approach concerns the narrow field of view upon a scene, within
which the visual attention is focused. Parallel
search (at the same time) might be a target and location whereas serially
(one at a time) includes searching for multiple targets. Everything within the spot can be processed
in parallel; things outside the spot, or peripheral vision, are processed
serially.
4.3 Control of Visual Attention
Control can be top-down (goal driven) or bottom-up (stimulus driven). [21, 22] Goal driven includes shifts of attention to spatial locations whereas stimulus driven is attentional capture by spatial cues, visual salience, and by abrupt visual onsets. The user employs strategies and intentions (i.e. looking for a target). When a person is searching for a featural target, then irrelevant targets will capture attention. However, when a person is searching for a more complex object, irrelevant featural targets will not capture attention. Stimulus driven attention is controlled by some salient attribute of the image that is not necessarily relevant to the user’s perceptual goals (i.e. selecting a moving target because it “pops out”.) When a person directs attention to a spatial location in advance of a display, then visual events that would otherwise capture attention will generally fail to do so. Stimulus driven control is both faster and more potent than goal driven attentional control due to the decision process that is required in goal-driven control.
Limitations of human attention which the automation designer must keep in mind include:
• Perceptual Processing Limitations – Increased perceived difficulty attending to more things at one time.
•
Focus of Attention - Impact of the
situation on the user in directing the attention and keeping it focused.
• Central Processing Limitations – Cognitive processes may be limited in number which can occur at a time.
• Memory – Long, Working, Short - relationship between attention, working memory, search, short-term retention.
• Modes of Attention - Top-down or Bottom-up
4.4 Guided Search to
control attention
Factors to consider when designing presentation from Level 4 to Level 5 include redundancy of information already monitored during passive supervisory control. It may be critical to avoid cluttering the information display when switching from passive monitoring to active open-loop decision-making Level 5 activities, since time is usually of the essence in closing the loop on the Level 5 user decision and returning the system to automatic control.
Semantics and Syntax of Information presentation: The syntax, or form, of the information presented to Level 5 should accommodate known human factors issues to expedite decision making and lead to best-case true-successful decisions more often than false-failure decisions based upon incomplete or confusing information presentation. Semantics, or content and context, of the information is also important to presentation. False-failures can be defined as decision failures (with respect to desired outcome) not from human decision making failure, but from arriving at the correct decisions with respect to faulty information which leads to an undesired or failed outcome. In other words, false-failures would not be the fault of the HIL, but of faulty system design in how information necessary for the decision was presented to the HIL.
Visual search strategies are employed in HIL monitoring of any Group Tracking activity, which indicates key human factors such as visual memory load, visual processing workload, and visual search difficulty for a Group Tracking exercise. These factors also must be incorporated into the design and modeling of Level 5 User Refinement. For instance, visual search strategies are trainable in part, and may generalize across different tasks, different locations within the visual field, and across eyes [25]. It is also proposed that visual working memory usage does not negatively impact visual search, except perhaps a slight latency. [26] These factors in visual and other modalities must be researched and accounted for in particular implementations of presentation of fused sensor data for time-critical decision making. The LOA selected will depend on the nature of the interactions of the HIL attention factors with the automation. Finally, training of the HIL, or the novice status or expert status of the HIL, must be taken into consideration for both multi-modal attention parameters.
4.5 Trust in Automation
Several theories and working models of trust in automation for the HIL have been proposed and incorporated into both research and design. Information which is presented for Decision-Aiding to the HIL is not uniformly trusted and incorporated into SA. Rempel, in 1985, proposed three increasing levels, or ‘stages of trust’, modeled on human-human interactions: Predictability, Dependability, and Faith. Participants progress through these stages over time in a relationship. The same was anticipated in human-automation interactions, either via training or experience. The main idea is that as trust develops, the HIL will make decisions based upon the trust that the system will continue to behave in new situations as it has demonstrated in the past.
Trust issues in automation have been characterized and researched by Muir and Moyer. “The human operator’s role in today’s highly automated systems is to supervise the automation and to intervene to take manual control when necessary. An important determinant of operators’ choice of manual or automatic control may be their degree of trust in the automation. The model of human trust was developed by taking models of trust between people as a starting point and extending them to the human machine relationship.” [27]
Another construct of trust related to automation, outlined by Barber,
1983, and reviewed by Endsley, outlines the following:
• Persistence – an expectation of constancy and predictability.
• Technical competence – Expert knowledge, Technical facility, Routine performance
• Fiduciary responsibility – Expectation that the automation will meet its design-based criteria for performance in domains where the machine has superior knowledge, authority, and/or power.
Sheridan [24] has written prolifically on automation and supervisory control. A review of this body of work is suggested to outline concepts of reliability, robustness, familiarity, understandability, explication of intention, usefulness, and dependence of automation to the user. Muir & Moray [12] built upon Rempel’s stages and postulated that
Trust = Predictability + Dependability + Faith + Competence + Responsibility + Reliability
Muir and Moray [12] further defined the construct of Distrust: (1) Can be caused by operator feeling that the automation is undependable, unreliable, unpredictable, etc. and (2) Set of dimensions related to automation failures, which may cause distrust in automated systems (Location of failure, Causes of failure or corruption, Time patterns of failure).
A tabular summary below, adapted below from Muir and Moyer [12], depicts the quadrant of trust and distrust behaviors with respect to good or poor quality of the automation. Basically, if the outcome of a wrong decision to trust the automation is worse than the outcome of a wrong decision to not trust the automation, then it is critical to present the user with enough training to know when to trust the automation.
Table 1. Trust, Distrust, and Mistrust, adapted from Muir and Moray 1996 [12]
|
Operator’s trust & allocation of function |
Quality of the automation ‘Good’ ‘Poor’ |
|
|
Trusts and uses the automation |
Appropriate Trust (optimize system performance) |
False Trust (risk automated disaster) |
|
Distrusts and rejects the automation |
False Distrust (lose benefits of automation, inc. workload) |
Appropriate Distrust (optimize system performance) |
 As noted earlier regarding attention,
modeling systems for SA to support successful decision making must take into
account the mental processing of information. Trust [28-30] in the automation clearly impacts the
mental processing model for decisions, and this impact changes over time and
experience with the automation. Therefore, dynamic models must be devised to
account for this aspect of the HIL. For the Human in the Loop to refine the
assessment for final decision that is passed up from Level 4 in an open
feedback loop, the user must have trust in the automation regarding the
validity and reliability of the information presented.
As noted earlier regarding attention,
modeling systems for SA to support successful decision making must take into
account the mental processing of information. Trust [28-30] in the automation clearly impacts the
mental processing model for decisions, and this impact changes over time and
experience with the automation. Therefore, dynamic models must be devised to
account for this aspect of the HIL. For the Human in the Loop to refine the
assessment for final decision that is passed up from Level 4 in an open
feedback loop, the user must have trust in the automation regarding the
validity and reliability of the information presented.
Note that at the macro level, supervisory control takes the individual operator fields of view and combines them into a battlefield or strategic theater view. Taking over from Level 4 to a Level 5 User Refinement means either assuming manual control of an individual remote sensor, tactician, or vehicle from the automated system. Situation awareness at both micro and macro levels will be necessary. Therefore the data and information processing algorithms must be able to be decoupled from the automated global or strategic synthesis from Level 0 through Level 4, such that individual system components can be isolated for the Level 5 User. Information fusion at the lower levels must be logged and state maintained of key variables to permit the necessary decoupling of fused information for precision decision override by the HIL at critical points in a supervisory scenario.
 Adequate and precise training and design
iterations to present the information successfully in both fused and decoupled
paradigms will require extensive testing to achieve good situation awareness
for the HIL.
Adequate and precise training and design
iterations to present the information successfully in both fused and decoupled
paradigms will require extensive testing to achieve good situation awareness
for the HIL.
5. USER REFINEMENT for GROUP Tracking
Group tracking is the ability to prosecute a set of targets in the environment. Such issues as occlusions and relations among targets are key attributes which make the workload and attention for the user different than a single target tracking problem.
5.1 Group Definition
We define a group as a collection of targets that are spatially and temporally similar, move together, and have the same allegiance. For the case of spatial similarity, we use the validation region of a tracking system to define where the targets occupy similar space. The temporally similar targets are cases where the group of targets are near to each other in the same time instant. Targets that move together can be defined as a group by direction and speed. We use past information to determine the movement history. Finally, the allegiance of the targets relies on the identity of the targets within the group. In the case that similar groups join as a single unit force, the group detector assumes targets that are of the same allegiance and movement. Likewise, targets which are spatiotemporally dissimilar are split into separate groups.
 To reduce the workload to the human, we use
the fusion system to group targets using a belief measurement. The belief in
the target ID is related to the group, allegiance, object-type, and location
information. For the case that a sensor
is cued to observe the object, it’s identity is
calculated through beliefs of the object type which is determined from an
automatic target recognition (ATR) algorithm from the fusion of various sensors
or the trust the human has in the display. To update the confidence in the
Group ID, we include various definitions of groups as shown in Table 2.
To reduce the workload to the human, we use
the fusion system to group targets using a belief measurement. The belief in
the target ID is related to the group, allegiance, object-type, and location
information. For the case that a sensor
is cued to observe the object, it’s identity is
calculated through beliefs of the object type which is determined from an
automatic target recognition (ATR) algorithm from the fusion of various sensors
or the trust the human has in the display. To update the confidence in the
Group ID, we include various definitions of groups as shown in Table 2.
 The definitions for group tracking follow
from the location, movement, target attributes, and the group allegiance. One difficulty arises if the members of
different groups include targets of the same type and allegiance which merge,
split, or cross. For a scenario in which
similar target types can be members of multiple groups, we use human user
refinement for feedback of kinematic information to determine which of the same
target types belong to which groups. To accommodate crossing groups, we delay
the merging decision until sufficient time has been acknowledged to determine
which targets belong to which groups based on a movement history. In this case, human information helps
determine group identity. Table 3 shows the benefits of group tracking.
The definitions for group tracking follow
from the location, movement, target attributes, and the group allegiance. One difficulty arises if the members of
different groups include targets of the same type and allegiance which merge,
split, or cross. For a scenario in which
similar target types can be members of multiple groups, we use human user
refinement for feedback of kinematic information to determine which of the same
target types belong to which groups. To accommodate crossing groups, we delay
the merging decision until sufficient time has been acknowledged to determine
which targets belong to which groups based on a movement history. In this case, human information helps
determine group identity. Table 3 shows the benefits of group tracking.
5.2 Group Tracking with User Refinement
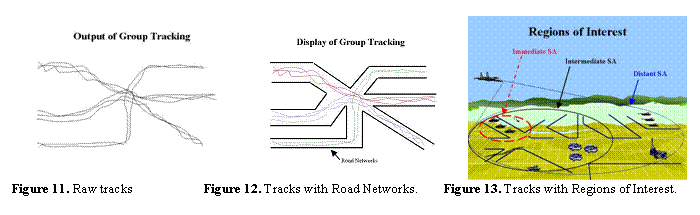 In our study of group tracking with a user,
we first started with the raw tracks. By
investigating the display, we incorporated 1) directing attention, 2) reducing
the workload, and 3) improving trust. In
Figure 11, the raw tracks are presented.
At first it was difficult to discern tracks. To direct attention, we included road
networks which also increased trust, as shown in Figure 12 Second, we use
color and different lines that reduced the workload. Finally, we looked at displaying regions of
interest to facilitate understanding the threat and directing attention to
nearer targets (shown in Figure 13).
In our study of group tracking with a user,
we first started with the raw tracks. By
investigating the display, we incorporated 1) directing attention, 2) reducing
the workload, and 3) improving trust. In
Figure 11, the raw tracks are presented.
At first it was difficult to discern tracks. To direct attention, we included road
networks which also increased trust, as shown in Figure 12 Second, we use
color and different lines that reduced the workload. Finally, we looked at displaying regions of
interest to facilitate understanding the threat and directing attention to
nearer targets (shown in Figure 13).
Designing the tracking algorithms with the goal of Level 5 User Refinement requires determining the severity of trust outcome failures, and mitigating these. Therefore, the issues such as reliability of the system and validity of the information presented by the system are accounted for in modeling and design of Level 5 interactions regarding achieving appropriate trust of the HIL for the system. Finally, training of the HIL is an ongoing necessity to maximize the effect of the User Refinement upon the tracking model.
6. CONCLUSIONS
This article overviewed some current fusion models and demonstrated the importance of the human in a fusion model. The higher-level fusion issues of control, decision, and action need to be addressed in current fusion system designs to effectively include the human in prosecuting target localization and identification. For the development of a human-machine inter-active fusion model, the use of the human in a Level 5 process was further assed using situation awareness, trust, attention, and workload measures. Results show that designing for User Refinement, with respect to HIL attention, workload and trust in the automation, can enhance the accuracy of the target localization and group identity.
7. REFERENCES
[1] Y. Bar-Shalom, and Li, X. R. Multitarget-Multisensor Tracking: Principles
and Techniques. Storrs, CT: YB
[2] A.
Blake and M. Isard, Active contours : the application of
techniques from graphics, vision, control theory and statistics to visual
tracking of shapes in motion, Springer,
[3] E. P. Blasch and J. C. Gainey Jr.,
“Physio-Associative Temporal Sensor Integration”. SPIE App. and Science of Computational Intelligence, Orlando, FL,
April 13-17, 1998. pp. 440 – 450.
[4] M. Bedworth and J. Obrien, “The Omnibus Model: A New model of data fusion?”, AES Magazine, April
2000.
[5] A.N. Steinberg, C. L. Bowman, and F. E.
White, “Revisions to the JDL Data Fusion model,” NSSDF, 1999, pp. 235 - 251.
[6] Endsley, M.R. (1987a) SAGAT:
A methodology for the measurement of situation awareness. Hawthorne, CA:
Northrop Corp.
[7] Endsley (1987b) The application of human factors to the development of
expert systems for advanced cockpits. Proceedings of the Human Factors Society
31st Annual Meeting (pp. 1388-1392). Santa Monica, CA: Human Factors
Society.
[8] Endsley, M.R. (1988). Design and evaluation for situation awareness enhancement,
Proceedings of the Human Factors Society 32nd Annual Meeting (pp.
97-101). Santa Monica, CA: Human Factors and Ergonomics Society.
[9] Collins,
R.T.; Lipton, A.J.; Fujiyoshi, H.; Kanade, T.,
“Algorithms for cooperative multisensor surveillance” Proceedings of the IEEE , Volume: 89 Issue: 10 , Oct. 2001 : 1456 –147
[10] Kadar, I, “Perceptual
Reasoning in Adaptive Fusion Processing,” SPIE, 2002.
[11] Jedrysik et. al., “Interactive Displays for Command and Control”
Aerospace Conf., IEEE , Volume: 2 2000 : 341 -351
[12] Muir, B. and Moray, N.
(1996). Trust in automation: Part
II. Experimental studies of trust and
human intervention in a process control simulation. Ergonomics, 39 (3), 429-460.
[13] Kaber, Onal,
Endsley, “Design of Automation for Telerobots and the Effect on Performance,
Operator Situation Awareness, and Subjective Workload”, Human Factors and
Ergonomics in Manufacturing, Vol 10 (4) 2000 :
409-430
[14]
Selcon, S.J.
and Taylor, R.M. (1989). Evaluation of the situational
awareness rating technique (SART) as a tool for aircrew systems design. In Situaion Awareness in
Aerospace Operations (pp. 5/1-5/8).
[15] Hart, S.G., & Staveland,
L.E. (1988). Development of NASA-TLX (Task Load Index): Results of empirical
and theoretical research. In. P.A. Hancock & N. Meshkati (Eds.), Human
Mental Workload (pp. 139-183).
[16] Gilson,
[17] Mayer, R.E. (1983) Thinking, problem solving, cognition.
[18] Rouse, W.B. and
[19] VanDijk, T.A. and Kintsch, W. (1983) Strategies of
discourse comprehension. New York: Academic Press.
[20] Rasmussen, J. (1986) Information processing and human-machine interaction: An approach to
cognitive engineering. New York: North-Holland.
[21] Pashler,
H. (1998). Attention. East Sussex, BN, UK: Psychology Press, Ltd.
[22] Ware,
C. (1999). Information visualization : Perception
for design. San Francisco: Morgan Kaufman Publishers.
[23] Naatanen, R. (1992).
Attention and brain function. New Jersey: Lawrence Erlbaum
Associates, Inc.
[24]
[25] Sireteanu, S. &
Rettenbach, R. (2000). Perceptual learning in visual
search generalizes over tasks, locations, and eyes. Vision Research (40):
2925-2949.
[26] Woodman, G.F., Vogel, E.K., and Luck, S.J.( 2001) Visual Search Remains Efficient When Visual Memory
is Full. Psychological Science Vol 12 (3): 219-224.
[27] Muir, B. (1994). Trust in automation: Part I. Theoretical issues in the study of trust and
human intervention in automated systems.
Ergonomics, 37 (11), 1905-1922.
[28] Bisantz,
A., and Seong, Y. (2001). Assessment of operator
trust in and utilization of automatic decision-aids under different framing
conditions. International
Journal of Industrial Ergonomics, 28, 85-97.
[29] Lee, J. and Moray, N.
(1992). Trust, control strategies and
allocation of function in human-machine systems. Ergonomics, 35 (10), 1243-1270.
[30] Raeth,
P. and Reising, J. (1999). Transitioning basic research to build a dynamic model of pilot
trust and workload allocation. Mathematical
and Computer Modeling, 30, 149-165.